
摘要
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常见的统计方法,用于评估一个词对于一个文档集或一个语料库中的其中一份文档的重要性。本文将全面阐述TF-IDF的通俗理解、技术原理、应用场景,并做以总结。
通俗理解
TF-IDF是一种量化文本中关键词重要性的指标,其核心思想在于:如果某个词在一篇文章中出现次数较多(词频高),并且在其他文章中出现次数较少(文档频率低),则认为这个词对于这篇文章来说是重要的。简而言之,TF-IDF衡量的是某个词在特定文档中与整个语料库中的重要性。
技术原理
TF-IDF的计算由两部分组成:词频(TF)和逆文档频率(IDF)。
- **词频(TF)**指的是一个词在文档中出现的次数,它是一个直观的衡量标准,表示词在文档中的相对重要性。
- **逆文档频率(IDF)**是衡量词的普遍重要性的一个指标,它由一个词在所有文档中出现的频率的倒数的对数得到。计算公式如下:
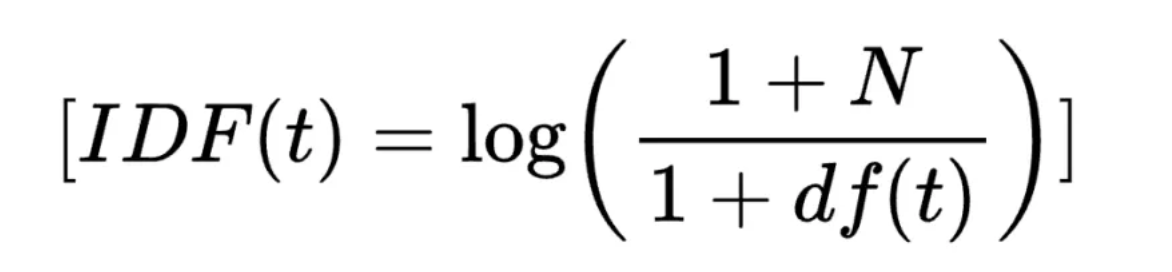
其中,( t ) 是一个词,( N ) 是文档总数,( df(t) ) 是包含词 ( t ) 的文档数。
TF-IDF的最终得分则是TF和IDF的乘积:
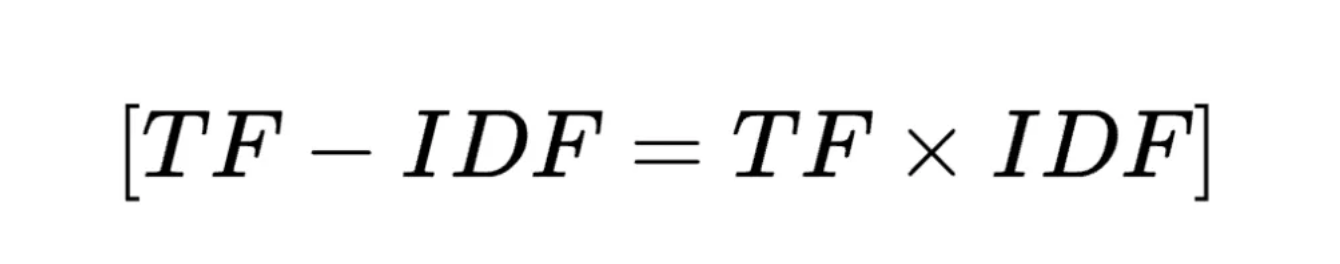
应用场景
TF-IDF有多种应用场景,以下是一些典型的用途:
- 文本挖掘:在文本挖掘中,TF-IDF可以用来识别文档中的关键词汇,帮助理解文档的主要内容。
- 信息检索:在搜索引擎中,TF-IDF可以帮助评估查询词与文档的相关性,进而改进搜索结果的排名。
- 自然语言处理:在自然语言处理任务中,比如分类、聚类等,TF-IDF常被用于特征提取,将文本数据转换为机器学习模型可以处理的数值数据。
- 推荐系统:在推荐系统中,TF-IDF可以用于分析用户评论,提取产品特征,以提高推荐的准确性。
总结
TF-IDF是一个强大的文本分析工具,它可以帮助我们从大量的文本数据中提取关键信息,并应用于多种场景,如文本挖掘、信息检索和自然语言处理等。通过计算词频和逆文档频率的乘积,我们可以得到一个词在特定文档中的相对重要性,进而实现对文本数据的有效分析和处理。
🔥 热门文章推荐(2AGI.NET)
扫码加入社群,参与讨论

AGI (103) AI Agent (3) AI App (1) AI Celebrity (9) AIGC (167) AI 名人堂 (9) AI 搜索 (1) AI 教程 (2) AI教程 (12) AI生产力平台 (1) AI电影制作 (2) Claude (1) claude 3.5 sonnet (1) Coze (2) DeepSeek (5) GAN (1) kimi.ai (2) kimi ai (4) kimi app (4) Kimi app AI (6) LLM (1) LoRA (1) Michael I. Jordan (1) NotebookLM (1) OTA AI (1) RAG (2) trae (2) Transformer (1) 一站式解决方案 (1) 人工智能 (2) 优化算法 (1) 内容创作 (1) 天天 AI (84) 天天AI (2) 技术原理 (32) 机器学习 (2) 李飞飞 (2) 梯度下降 (1) 模型微调 (2) 热点资讯 (87) 百度 (1) 秒刷 (1) 行业资讯 (1) 贝叶斯网络 (1) 酒旅AI产品对比 (1) 领域热词 (43)